SMF: Template-free and Rig-free Animation Transfer using Kinetic Codes
SIGGRAPH Asia 2025 [ACM Transactions on Graphics]
* Equal contribution
Abstract
Animation retargeting involves applying a sparse motion description (e.g., 2D or 3D keypoint sequences) to a given character mesh to produce a semantically plausible and temporally coherent full-body mesh sequence. Existing approaches come with a mix of restrictions -- they require access to template-based shape priors or artist-designed deformation rigs, suffer from limited generalization to unseen motion and/or shapes, or exhibit motion jitter. We propose Self-supervised Motion Fields (SMF), a self-supervised framework that is trained with only sparse motion representations, without requiring dataset-specific annotations, templates, or rigs. At the heart of our method are Kinetic Codes, a novel autoencoder-based sparse motion encoding, that exposes a semantically rich latent space simplifying large-scale training. Our architecture comprises of dedicated spatial and temporal gradient predictors, which are jointly trained in an end-to-end fashion. The combined network, regularized by the Kinetic Codes' latent space, has good generalization across both unseen shapes and new motions. We evaluated our method on unseen motion sampled from AMASS, D4D, Mixamo, and raw monocular video for animation transfer on various characters with varying shapes and topology. We report a new SoTA on the AMASS dataset in the context of generalization to unseen motion. Source code and models will be released on acceptance.
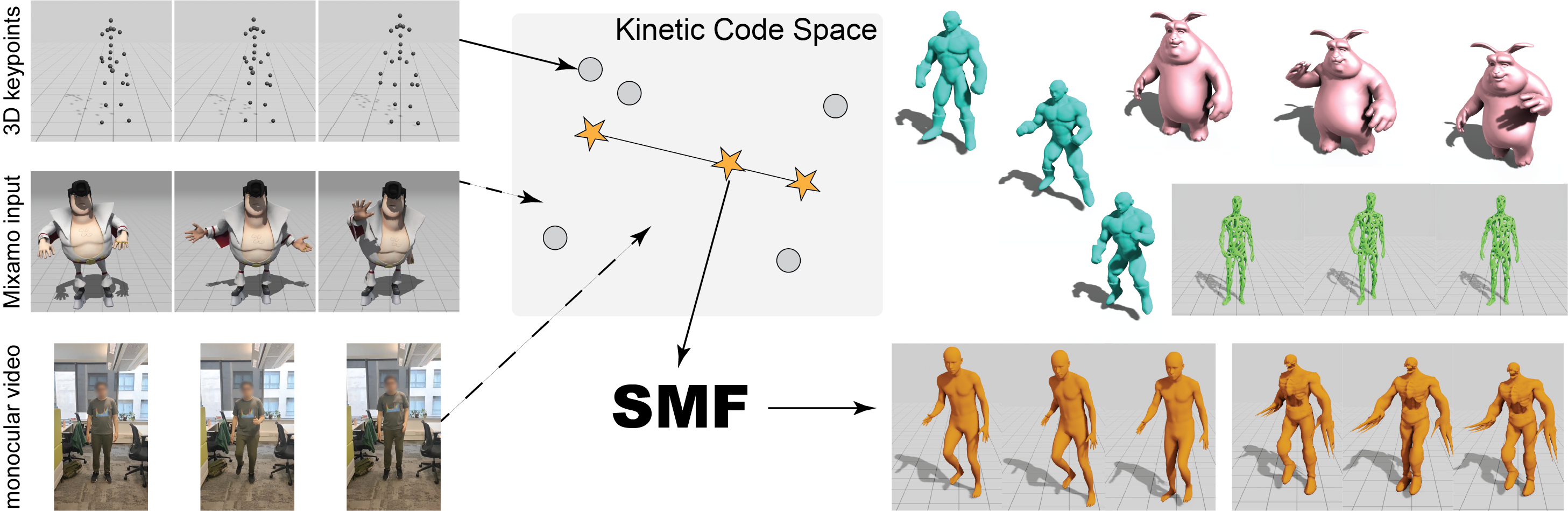
We present a self-supervised method to transfer coarse motion sequences,
embedded in a learned Kinetic Code (KC) space, to full body motion. Samples from the KC space can be consumed by our method, Self-supervised Motion
Fields (SMF), to produce mesh animations. Our method is trained with sparse signals and can be used for motion interpolation . We do not assume access
to any morphable model, canonical template mesh, or deformation rigs. Left shows various sparse motion inputs (3D keyframes, Mixamo sequences, or
monocular video) that can be embedded into the learned KC space and decoded, and consumed by temporally coherent motion prediction via SMF to produce
animations for different characters (right), with varying topology and shapes. SMF can faithfully transfer human motion to non-humanoid characters.
Results
Motion sequences from AMASS
We compare our method on a wide variety of unseen motion transfer from AMASS to varied meshes with significantly different shape and topology. All results show transferred (unseen) motion to an unseen in-the-wild shape without rigging.
Motion transfer to humanoids
Motion transfer to non-humanoids
SMF shows strong generalization from human source motion to non-humanoid characters (octopus, hand, scissor). Even though the characters possess multiple arms for example, SMF produces plausible motion without artifacts.
Comparison
Motion sequences from Mixamo (Out-of-Distribution dataset)
We present results on motions sampled from the Mixamo dataset, which are transferred to diverse, unseen shapes using their 3D keypoints. To automate the process of establishing correspondence, we use Diff3F to find matching keypoints between AMASS and Mixamo. Although these correspondences can be noisy due to imperfectly overlapping keypoint locations, our method (SMF) faithfully transfers the motion. This robustness is attributed to its Kinetic Code, which enables a smooth and continuous encoding of the motion.
All Mixamo motions are completely unseen (ours and all baselines except Skeleton-free are only trained on AMASS). Note, Skeleton-free requires the complete mesh as input and it is additionally trained on Mixamo data.
Compared to ours, other methods fail to transfer the motion faithfully and/or result in numerous artifacts.
Motion sequences from AMASS
Error Analysis
Notice the incorrect pose and presence of artifacts for baseline methods. Skeleton-Free Pose Transfer suffers from artifacts and unnatural deformations seen in the arms, pelvic and stretching of the neck (please zoom-in). Errors are highlighted in red. Note: Skeleton-Free Pose Transfer requires the complete source mesh as input compared to our sparse keypoints setup which is easier to author but more challenging to transfer.
Click the below button to switch between different motions.
Unseen Motion Transfer to in-the-wild stylized characters
Motion transfer to in-the-wild characters gathered from Mixamo, Sketchfab, etc.
Unseen Motion Transfer to non-humanoid characters
Motion transfer from human source to non-humanoid characters gathered from D4D and Sketchfab.
Interpolation of Kinetic Code
Our Kinetic Code offers a smooth latent space for realistic motion interpolation. We mix different motion categories and transfer it to different characters. In contrast, we see interpolation of mesh vertices (ground truth source) in the Euclidean space leads to flattening of the hands in Knees + Shake Arms as they move in different directions. In One Leg Jump + Punching, we see the punching being preserved compared to the downwards punching motion in euclidean space.
2D monocular capture to unseen 3D target shape
We transfer motion from 2D monocular capture to an unseen in-the-wild 3D mesh without any rigging or template. This is a very challenging scenario and we use our 2D motion representation for solving this. While the transferred motion is not perfect and there are artifacts, ours is the first method capable of performing it without requiring a template shape.
Motion sequences from DeformingThings4D (D4D)
To show that our method works on animals, we train our method on motions from the DeformingThings4D dataset, which provides animal 4D meshes as deforming sequences and test it on unseen motion sequences.
Long Motion Sequences
We compare 𝑆𝑀𝐹 and the only other temporal baseline-- TRJ on an unseen folk dance sequence (10000 frames) from the AMASS dataset. As the sequence progresses, TRJ accumulates significant error, monotonically exacerbating distortion artifacts (notice how the shape gets streteched vertically towards the end). In contrast, 𝑆𝑀𝐹 follows the source motion more closely, demonstrating 𝑆𝑀𝐹 's robustness to temporal drift and its suitability for generating long motion sequences.
Note: This video has been fast-forwarded by 3x compared to other videos shown in the webpage.
BibTeX
@misc{muralikrishnan2025smftemplatefreerigfreeanimation,
title={SMF: Template-free and Rig-free Animation Transfer using Kinetic Codes},
author={Sanjeev Muralikrishnan and Niladri Shekhar Dutt and Niloy J. Mitra},
year={2025},
eprint={2504.04831},
archivePrefix={arXiv},
primaryClass={cs.GR},
url={https://arxiv.org/abs/2504.04831},
}